
第十三期CCF-CV“视界无限”系列研讨会成功举办

2022年5月17日,由中国计算机学会计算机视觉专委会举办的第13期CCF-CV“视界无限”系列活动——“视觉Transformer与Attention的前沿进展与未来趋势”研讨会在线上举办。研讨会邀请了专委会副主任中科院自动化所王亮研究员致辞,清华大学鲁继文、南京大学王利民、复旦大学张力、南开大学侯淇彬、清华大学国孟昊做主题报告。南开大学程明明教授及以上五位讲者参与了深度研讨。计算机视觉专委会B站公众号对本次会议进行了全程直播,直播人气峰值达到1400+。
嘉 宾 致 辞

王亮副主任介绍了活动的情况。本次研讨会是计算机视觉专委会举办的“视界无限”系列活动第十三期,也是2022年的第二场活动。他指出Transformer与Attention是当前视觉领域最前沿最活跃的研究方向之一。Transformer这种机制不仅适用于自然语言处理方向,在计算机视觉中亦有非常广阔的应用前景。该方向发展很快,同时也存在很多实际的困难和挑战。借由本次活动,大家可以与该领域的优秀专家学者就研究现状做一次深度研讨,一起探索未来可能的发展趋势。最后,王亮副主任对研讨会组织者及各位青年学者表达了感谢,并预祝本次会议圆满成功。
主 题 报 告
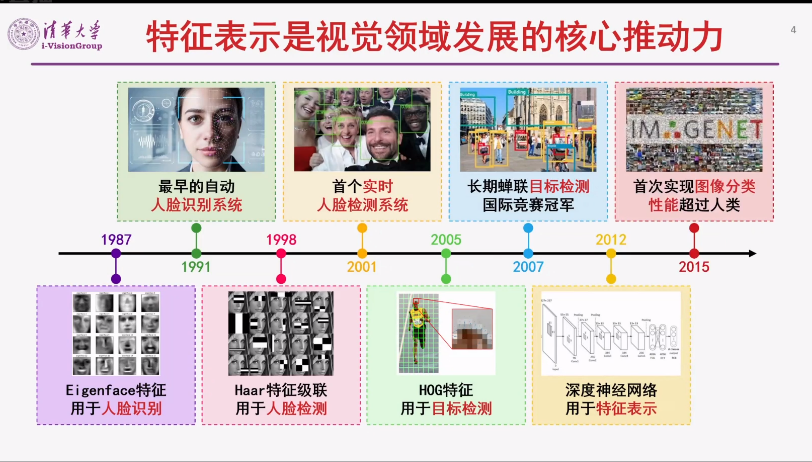
鲁继文副教授的报告题目是“视觉基础模型及应用”。基础模型是人工智能领域的研究热点,在计算机视觉和自然语言处理等多个领域中均取得了优异的性能,是视觉监控、自动驾驶、智能终端等重要应用的支撑性技术。鲁继文副教授从模型架构和学习范式两方面回顾视觉基础模型近年来的研究进展,同时介绍清华大学智能视觉实验室在视觉基础模型方面所开展的工作,包括动态稀疏模型、全局滤波模型、球面分形模型、几何敏感模型等,以及它们在目标检测与分割、物体分类与识别、图像与视频检索、三维重建与识别等视觉任务中的应用。

王利民教授的报告题目是“基于注意力机制的视频表征学习与目标跟踪”。视频理解已经成为人工智能研究的热点和难点,其中人体动作识别是视频理解涉及的关键技术之一。王利民教授主要介绍南京大学媒体计算组(MCG)在视频动作识别和目标跟踪方面的系列工作。首先,针对视频运动表征与建模,介绍了高效和动态的时序建模模块(TEINet,TAM,TDN), 在计算效率和建模精度方面取得较优效果。其次,针对视频模型的自监督预训练,介绍了基于掩码自编码器的视频高效学习方法VideoMAE,验证了MAE一种数据高效的Transformer自监督训练框架,并且在动作识别主流数据库上取得了优异的识别性能。最后,针对视频目标跟踪技术,介绍了更加简洁的单目标跟踪框架MixFormer,统一了特征提取和特征融合模块,在5个主流跟踪数据集都取得了目前最好的跟踪精度。最后总结和展望了视频理解的发展趋势。

张力研究员的报告题目是“不依赖于 Softmax 的线性复杂度自注意力模型”。Vision transformers推动了各项视觉识别任务的进展,但是在计算和存储方面都存在二次复杂度。具体来说,传统的自注意力计算需要对特征向量之间的点积缩放后进行 softmax 归一化。保持该softmax操作对任何线性化的方法都是一个障碍。张力研究员介绍了不依赖于 softmax的Transformer模型,使用无行归一的高斯核函数来代替之前的点积注意力,并基于此构建低秩的矩阵分解逼近满注意力矩阵。采用Newton-Raphson 方法来保证近似的鲁棒性并实现近似中涉及的 Moore-Penrose 逆计算。在大规模图像识别数据集 ImageNet上的实验表明该线性化方法能够显著提升现有Transformer模型的计算效率,获得准确性和复杂性之间更优越的权衡。

侯淇彬副教授的报告题目是“如何更好地训练视觉Transformer”。近年来,视觉Transformer推动了视觉领域多项识别任务的发展。在多数视觉任务中,基于Transformer的网络结构在性能方面已逐渐优于传统的CNN网络。侯淇彬副教授介绍了如何借助CNN精准定位目标物体的能力,进一步提升视觉Transformer的性能。基于这个动机,提出了Token Labeling的训练策略,通过给视觉Transformer的每个输出Token赋予一个来自CNN预测结果的监督信息,可有效提升视觉Transformer的识别能力。该工作同样说明基于Token Labeling训练策略的预训练模型在语义分割等下游任务中仍有较好的表现。

国孟昊博士的报告题目是“视觉注意力网络”。认知科学中,注意力机制是指在处理信息时,人类会选择性的关注重点的部分,而忽略一些无关的信息。近来,注意力机制在计算机视觉中得到了广泛的关注,基于自注意力机制的视觉Transformer 模型已经在各种视觉任务中取得了巨大的成功。本次报告,国孟昊主要以计算机视觉中的注意力机制为中心,重点讨论了三个问题:(1)当我们在谈论视觉注意力的时候,我们在谈论什么?(2)视觉 Transformer 的成功之道以及它存在的不足之处。(3)一种不同于 Transformer 的新型视觉注意力网络。
Panel 环 节
在 Panel 环节,与会嘉宾就“视觉Transformer与Attention的前沿进展与未来趋势”、“视觉Transformer与CNN如何共存”、“资源受限的条件下如何进行视觉Transformer研究”、“视频相关任务中Transformer的现状”等问题展开深入讨论,并就B站直播室观众的问题分享了各自的观点。
Panel 实 录
程明明:非常感谢5位老师的的精彩分享。Vision Transformer是目前视觉领域最热点的研究领域之一,在很多经典的任务上已经取得了成功,但是我们也能够看到它跟CNN相比依然有一些问题或者不足,比如Transformer最开始是针对一维数据设计的,并不是针对2D图像。下面想请各位老师探讨一下与CNN相比,Transformer的优势和劣势分别是什么?我们先请鲁继文老师谈一谈。
鲁继文:我觉得Transformer 这两年这么火或者这么受关注,根本原因是它刷新了模型性能的SOTA,与CNN相比,我觉得它很重要的一点是能够实现多任务的联合统一建模。主要的不足我个人感觉还是对数据的依赖性比较严重。Transformer很多模型在下游的小数据集上实验还是比较难work。CNN发展了有很多年了,应用范围也很广,但是它的问题在于面对大规模数据集的时候不适合去训一个大模型,尤其我们现在这个大模型时代,大家都希望能够去把大量的数据喂给模型训练,这也是Transformer比CNN流行的一个原因,但它们各有优劣。
张力:Transformer和它这样一种Self-attention的机制已经驱动深度学习快速发展。回顾五年以前,神经网络就是卷积和池化,我们以后会觉得这种方式很naive。那么这种卷积网络的上限并不是深度学习的上限。重新来看这个Transformer结构,可以认为它是一个动态的卷积。那么卷积其实是一个具有很强先验的一种运算方式。Transformer突破了这个上限,它通过学习自己乘以自己这样一个模式能够更好地泛化到测试集上,这也是它比CNN更加高效的一个原因。
王利民:CNN是从local到global这样一种学习方式,它局部的一致性会强一点,全局结构性是依赖于局部的。但是,像ViT这种结构它都是全局的操作,我觉得他本质上是一个更加灵活的方式。我们可以想象CNN是一个箱子来装东西,他方方正正的。相反,Transformer可能类似于像一个气球,这里什么样形状的数据,你放进去它可能就能跟你贴合的很好。还有就是Transformer其实是在提取一些低频的特征,相反,CNN可以抽取一些高频的特征。
程明明:谢谢各位老师的精彩发言。接下来还有一个问题在B站直播间出现了好几次,有同学在提问说这种视觉注意力机制在处理点云补全会有一些可能数据量比较大的困难,不知道各位老师对这个有什么看法,鲁老师是不是有做过这方面的工作?
鲁继文:去年我们实验室做了一个点云补全的工作,发表在ICCV上。点云补全这个任务,我们为什么可以用Transformer来做?很核心的问题是因为我们把这个任务建模成机器翻译的任务。机器翻译,我们都知道从中文到英文,从英文到中文,它实际上是一个转换的系统。点云补全我们把它建模成已知一部分点云,把残缺的点云补出来。实际上,我们也认为考虑到网络的预测能力或者翻译能力,这样去做实际上还是有一些难度的。这种点云数据其实与图像相比或者跟自然语言处理相比,它数据量是很小的,所以还是需要依赖一些已有的模型的架构去做一些初步的或者说做一些特别的表示,表示完之后我们再去做这个点云和点云之间的自注意力,通过Transformer去建模,这样可以把那些残缺的点云补全出来。场景点云和物体点云相比,场景点云更复杂,残缺的部分比重更高同时噪音更大,所以目前我们正在看看能不能在这种大场景下能够帮他做一些好的性能提升。
程明明:接下来还有一个问题就是现在学术界出现了很多像ConvNeXt,VAN这种比较好的CNN网络,那如何看待CNN和ViT的未来发展趋势?
侯淇彬:我可以先简单聊一下。目前为止大部分视觉任务其实还是比较单一的,就是说他只针对图像数据。但是以人为例,我们做人工智能算法肯定还是希望能够像人脑系统一样去处理不同的信号。目前,Self-attention机制不管在音频、视频、图像、语言等领域都是有较好表现的,我个人觉得我们需要把不同模型结合起来,以Transformer为骨干网络,针对不同任务的结构以Attention或者动态路由的形式加入到骨干网络中。比如在处理2D图像时,我们可以用国孟昊提出的visual attention这样的方法。
鲁继文:现在做视觉技术模型,实际上模型的结合是大势所趋,取长补短。我们经常说CNN有CNN的优点,Transformer有Transformer的优点,所以取长补短之后一定是有助于提高模型的性能。包括最近谷歌提出的CNN模型实际上也都借鉴了Transformer的设计思想。我们最近也发现了Transformer一个很好的性质。其实CNN网络具有比较好的平移不变性,在很多硬件以及优化的很好的情况下,如果进一步把卷积操作改进好,然后再结合Softmax,可以取得一些更好的性能。
张力:我们今天更多的在谈论注意力机制,但是Transformer这个模型除了自注意力机制以外他还有一些其他的特点,比如说他有物体感知的能力。物体感知能力是我们整个视觉最为核心的部分。比方说,我们要做目标检测,最早我们用selective search,包括程老师之前也做过Bing。后来的RCNN就能够把这种proposal融入到整个深度学习框架当中。通过这种方式,能够产生物体感知。在深度学框架里面,后来发现这种Transformer的Encoder能够提升物体的表征能力。然后,去年还是前年有一篇文章,说Encoder不仅能够提升我们视觉感知的表示能力,Decoder也能够重新定义计算机视觉的很多任务,比如目标检测。我们可以通过Transformer里面的这种查询机制去做这样的感知。像目标检测、实例分割、pose等都可以用这种方法来重新定义任务。所以,他除了这种特征表达能力以外,还有一些功能性的优势,能够重新帮助我们怎么去思考。
程明明:还有一个问题是ViT主要的成功来自于用self-attention 这样一种空间的注意力机制,如果说是从注意力机制本身出发的话,各位老师能不能谈一下在未来还有哪些可以进一步挖掘的方向?
国孟昊:我觉得空间注意力可以从两个角度谈这个问题。第一个就是空间的角度,第二个就是注意力这个角度。从空间的角度来看,其实传统方法带给我们的是一种空间的交互方式。比如CNN用3x3, 7x7这种卷积进行交互,然后就是像ViT这种直接全部都是全局的。第二个就是从注意力的角度,我认为其实他是一种聚合的方式,比如说VAN这种也是一种交互方式。从聚合方式的角度来看,其实到底能不能找一种新的信息聚合方式也是非常值得挖掘。所以我认为从空间和注意力两个角度应该是都能继续往下去做的。
程明明:B站直播间有同学想请各位老师说一说对于视频数据,还有哪些比较值得关注的。
王利民:我觉得视频的问题应该分几个层面来看,现在做视频的工作基本上就在follow CNN的解决视频问题思路,核心就是如何把self-attention操作从一个空间的操作变成时空的操作,但是这种简单的拓展能处理的视频的长度或者说帧数是比较有限的,所以说这只是一个初级的版本,只能处理几秒钟或者一两秒的视频。这个时候能理解的信息不是全方面的,而是受限的,只能做一些比较简单的运动识别。另外我觉得一个重要的点就是说我们怎么能处理更长的视频,那现在这个确实大家做的比较少,可能还得借鉴RNN的那种思路,把一些持续的信息做压缩,通过Memory的方式拓展到一个更长的视频乃至于一些更高层次的推理。
程明明:还有一个问题是ViT训练的过程中需要大量的计算资源,很多学校的学生特别是我们大部分的听众可能没有这么多的计算资源。如果说这些学生也想去做这个,有什么建议。比如说,各位老师能不能说一说自己一些比较有代表性的工作大概需要多少计算资源?
鲁继文:计算机视觉对算力的需求比较大,总是感觉算力的增长不能够满足广大同学们对GPU需求的增长。我始终坚持一个观点,就是学术界应该做适合学术界干的事,如果硬要去跟工业界PK这种数据和算力,我们很难找到自己的位置。所以一定要能够从这种偏idea层面去做。比如说我觉得我们去年做了两个视觉基础模型方面的工作,做的还不错。其实最后也就是几台机器就能够把这个事干了。我们说大模型也好,尤其我们谈视觉大模型,其实很多时候是一个系统工程,还有很多东西可以做。很多同学和老师可能关注到的只是模型的基础架构,因为模型架构方面的工作出来之后受关注度比较高。如果没有这个算力,很难找到我们的位置。早期Deep learning刚开始出来的时候,那个时候我实验室就一块卡,也做了一个深度度量学习的工作,后来这个工作的影响力也还不错。所以我坚持一个观点,就是要能够在整个视觉模型的训练、包括优化、推理等里面找到适合我们学术界干的事。
张力:慢慢这两年有一个新兴的方向叫做小型化模型。已经有一些paper了,比如说MobileViT,MobileFormer。都是已经开源的一些paper,这些模型都是小型化模型,非常小包括我现在那个腾讯的犀牛鸟项目也是在做这个Transformer的小型化。我们正在设计一个非常精小的模型,参数量和FLOPs都很小。这样一个小模型在ARM端去做测试跟MobileNetV3去比,速度啊,latency等都有优势。
程明明:王老师是做视频的,视频是不是对卡的需求更大一些?
王利民:我感觉未来的视觉或者说整个AI的发展的可能会逐渐收敛成一个刚才说的基础模型或者大模型,包括跟下游任务的适配。就是说当我们做基础模型时可能得依赖于一些更大的设备。但是当我们没有这样的设备或者平台的时候,可以优先考虑做一些下游的具体任务。关于具体任务,其实视频里面还有很多小的任务大家没有太关注到。因为做小的任务可以用现在的ViT,比如小样本训练。这一块其实对计算资源需求不是太大。所以说下游任务我觉得是一个很重要的方向。另外一个就是还是需要往更深入的理解这个角度去发展,可以做一些更精细的任务,比如做一些高效的模型。所以说,基础模型我们可以用现成的,然后我们可以做更多下游的任务,我是这样一个观点。
侯淇彬:关于Transformer这一块,我刚才也介绍了一个工作,从参数量的角度考虑,比如说最大的模型是150M,在最后测试的时候是512*512这样图像。对于小模型而言的话,比如ResNet50这种量级的模型,其实有8个V100就可以训练了。ViT不像以前CNN依赖BN,它用的是LN,因此4卡也可以训练。以V100为例,训练30M左右的一个模型,大概是需要两到三天的时间。如果是训练更大一点的模型,比如说150M这种模型,得采用两台V100,如果是在512*512的图像上微调,需要4个节点。如果大家资源不是很多,还是建议像之前各位老师说的那样做一下下游任务,比如显著性检测、Meta Learning、以及其他的模型独立的学习方法。
国孟昊:我们做的VAN tiny和small,在训练的过程中主要是8个3090显卡,训练两天左右。如果8块3090也不一定能拿的出来的话。其实可以像刚刚老师们说的那样做一些轻量级的网络或者说做一些其他任务。就是刚刚鲁老师说的那样,要做一些比较原创的东西,因为实验只是验证idea,如果洞察力够强的话,我觉得实验稍微弱一点也能做一篇非常好的工作,还是要拼idea,不要去拼计算资源。
程明明:用你的这个VAN模型去做一些语义分割的时候,可能需要多长时间?
国孟昊:其实如果去做语义分割的话,VAN用一张卡就能行,语义分割就比较不耗卡了,包括Base这种级别的其实就两张卡就够了,12个小时之内就能训完,对资源没有要求那么高。
程明明:好的,两张卡和12个小时,对部分同学来说已经是可以接受的了。看看大家还有什么更多的问题吗?咱们在报告的过程中,很多同学提出了问题,部分问题讲者老师已经在B站上留言解决了,我们就不再重复。有同学针对王老师这边有一个提问,请问王老师讲讲如何进行有效的长时和短时的特征融合?
王利民:我感觉这个问题还是非常好的。目前还是受限于硬件资源的限制,做常识性的基本上就两个思路:一个思路就是动态采样到一些有一定相关性的片段,然后对他们做一些动态模型来融合,这是一个思路;另外一个思路是不能够一次性的把它放到memory里面去,这时候可能得做一个memory bank,需要把特征存储起来,然后用它来辅助当前的一些短时的信号做决策,这是两种思路。
程明明:好的,有同学在问说decoder的这种query机制是不是可以做语义分割?
张力:这个思路已经有论文了,比如在全景分割里。
程明明:有同学想请王老分享一下在做视频训练的过程中对显卡的需求。
王利民:好的,我给大家就举一个例子吧,这个确实消耗很大。我们用自监督学习的方法训练一个视频的ViT,当时是跟腾讯合作的。我们跑的这个帧数有两个版本,一个是16帧的,就输入16帧,然后跑一个Base的模型,训练可能大概要2天到3天,然后用的是32张V100。所以说这个确实比较大,然后到后来我们投完稿之后,我们跑了一个ViT的大模型,跑的也是16帧,用了128块卡,然后跑了10天,但是那个数据量是到了50万左右,所以说数据量扩了一倍。这个开销确实比较大,所以说只能跟企业合作。
程明明:好的谢谢王老师。还有一个很重要的问题,也是大家很关注的问题,大家在训练的过程中,调参还是挺难的,各位老师在调参方面有什么样的经验可以跟大家分享吗?我看国博这边笑的比较开心,要不然你分享一下?
国孟昊:现在一些训练方法其实都已经写好了,比如说timm。根据他们的那些默认配置其实不怎么需要调。我一般调的时候就只调一个东西,就是Drop path rate。
程明明:再次感谢所有的讲者。大家有什么问题的话欢迎联系讲者,谢谢大家,我们今天的活动到此结束。
推荐内容
More >>>- · 第八十三期CCF-CV走进高校系列报告会于悉尼大学圆满结束
- · 第八十四期CCF-CV走进高校系列报告会于广东石油化工学院圆满结束
- · 第七十三期CCF-CV走进高校系列报告会于苏州科技大学圆满结束
- · 第七十四期CCF-CV走进高校系列报告会于河北大学圆满结束
- · 第七十期CCF-CV走进高校系列报告会于太原理工大学圆满结束
- · 第六十八期CCF-CV走进高校系列报告会于北京信息科技大学圆满结束
- · 第三届计算机视觉及应用创新论坛在广州举办
- · 第一届中国模式识别与计算机视觉大会在广州召开
- · CCF-CV专委会2018年度全体委员会议在广州成功举办
- · 【预告】CCF-CV走进高校系列报告会(第五十八期,广西师范学院)
 京公网安备11010802017125号
京公网安备11010802017125号